Voice Imitating Text To Speech Neural Networks
Our text to speech capability uses deep neural networks to overcome the limits of traditional text to speech systems in matching the patterns of stress and intonation in spoken language called prosody and in synthesizing the units of speech into a computer voice. We demon strate voice imitation using only a 6 seconds long speech sample without any other information such as transcripts.
Ai Is Giving Brands Eerily Human Voices

Voice Imitating Text To Speech Neural Networks

Mimic2 Is Live Mycroft Mimic Text To Speech

Fine Grained Robust Prosody Transfer For Single Speaker
Towards End To End Prosody Transfer For Expressive Speech
A 2019 Guide To Speech Synthesis With Deep Learning

Voiceloop Voice Fitting And Synthesis Via A Phonological Loop
Why You Should Be Worried About The Dark Side Of Synthetic

So the network really is just learning the tone of laymans voice as well as some commonly used sounds in his speech then it does its best to imitate them.
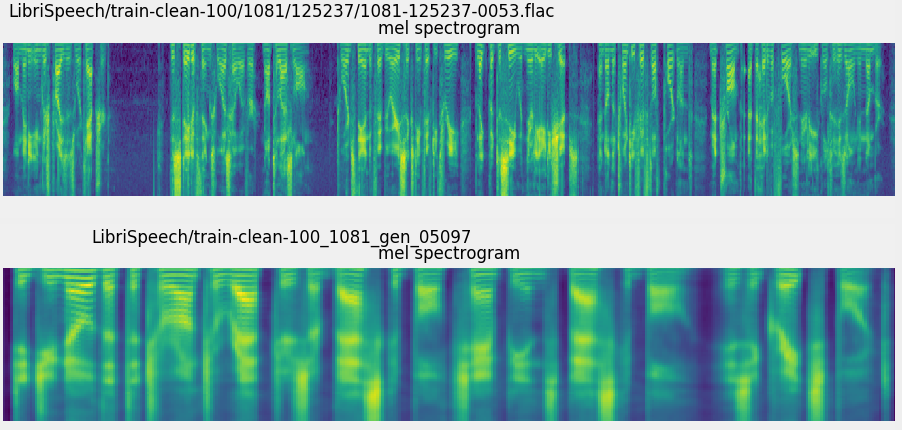
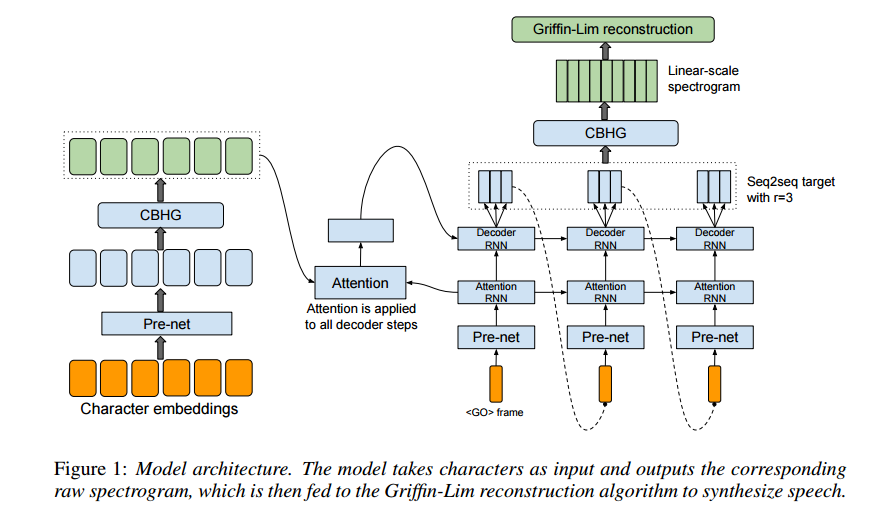
 Voice imitating text to speech neural networks. The ability of computers to understand natural speech has been revolutionised in the last few years by the application of deep neural networks eg google voice search. Voice imitating text to speech neural networks younggun lee 1taesu kim soo young lee2 abstract we propose a neural text to speech tts model that can imitate a new speakers voice using only a small amount of speech sample. Deep voice is inspired by traditional text to speech pipelines and adopts the same structure while replacing all components with neural networks and using simpler fea tures. Lyrebird was founded by alexandre de brébisson kundan kumar and jose sotelo in 2017 while phd students at mila studying under yoshua bengio who won the turing prize in 2019 for his pioneering research into deep learning and neural networks. However generating speech with computers a process usually referred to as speech synthesis or text to speech. This is 3 different recurrent neural networks lstm type trying. We propose a neural text to speech tts model that can imitate a new speakers voice using only a small amount of speech sample. Recently there is a surge of interest in speech synthesis with neu ral networks including deep voice 1 arik et al2017a deep voice 2 arik et al2017b deep voice 3 ping et al2018 wavenet oord et al2016a samplernn mehri et al2016. We implemented the voice imitating tts model by combining a speaker embedder network with a state of the art tts model tacotron. We implemented the voice imitating tts model by combining a speaker embedder network with a state of the art tts model tacotron. By popular demand i threw my own voice into a neural network 3 times and got it to recreate what it had learned along the way. We propose a neural text to speech tts model that can imitate a new speakers voice using only a small amount of speech sample. Unlike prior work which uses. We demonstrate voice imitation using only a 6 seconds long speech sample without any other information such as transcripts. We demonstrate voice imitation using only a 6 seconds long speech sample without any other information such as transcripts. Our model also enables voice imitation instantly without additional training of the model. Our model also enables voice imitation instantly without additional training of the model.
Voice imitating text to speech neural networks. The ability of computers to understand natural speech has been revolutionised in the last few years by the application of deep neural networks eg google voice search. Voice imitating text to speech neural networks younggun lee 1taesu kim soo young lee2 abstract we propose a neural text to speech tts model that can imitate a new speakers voice using only a small amount of speech sample. Deep voice is inspired by traditional text to speech pipelines and adopts the same structure while replacing all components with neural networks and using simpler fea tures. Lyrebird was founded by alexandre de brébisson kundan kumar and jose sotelo in 2017 while phd students at mila studying under yoshua bengio who won the turing prize in 2019 for his pioneering research into deep learning and neural networks. However generating speech with computers a process usually referred to as speech synthesis or text to speech. This is 3 different recurrent neural networks lstm type trying. We propose a neural text to speech tts model that can imitate a new speakers voice using only a small amount of speech sample. Recently there is a surge of interest in speech synthesis with neu ral networks including deep voice 1 arik et al2017a deep voice 2 arik et al2017b deep voice 3 ping et al2018 wavenet oord et al2016a samplernn mehri et al2016. We implemented the voice imitating tts model by combining a speaker embedder network with a state of the art tts model tacotron. We implemented the voice imitating tts model by combining a speaker embedder network with a state of the art tts model tacotron. By popular demand i threw my own voice into a neural network 3 times and got it to recreate what it had learned along the way. We propose a neural text to speech tts model that can imitate a new speakers voice using only a small amount of speech sample. Unlike prior work which uses. We demonstrate voice imitation using only a 6 seconds long speech sample without any other information such as transcripts. We demonstrate voice imitation using only a 6 seconds long speech sample without any other information such as transcripts. Our model also enables voice imitation instantly without additional training of the model. Our model also enables voice imitation instantly without additional training of the model. Nous partageons liés voice imitating text to speech neural networks que collecter. L'administrateur Exemple de Texte 2019 collecte également d'autres images liées voice imitating text to speech neural networks en dessous de cela. Visitez l'adresse source pour une explication plus complète.
Alexa Gets An Improved Voice And Can Now Sound Like Samuel L

Canadian Developer Says Voice Imitation Technology Raises

Voice Imitating Text To Speech Neural Networks

Fine Grained Robust Prosody Transfer For Single Speaker
You Can Now Speak Using Someone Elses Voice With Deep Learning
Google Ai Blog Google Duplex An Ai System For

Modulate Homepage
Pr12 165 Few Shot Adversarial Learning Of Realistic Neural

Speech Synthesis Techniques Using Deep Neural Networks
I Trained An Ai To Copy My Voice And It Scared Me Silly
Arxiv190101085v1 Cssd 4 Jan 2019
Fine Grained Robust Prosody Transfer For Single Speaker
Recurrent Neural Network Wikipedia
C'est tout ce que nous pouvons vous informer sur le voice imitating text to speech neural networks. Merci de visiter le blog Exemple de Texte 2019.
0 Response to "Voice Imitating Text To Speech Neural Networks"